The Null Hypothesis, the Alternative Hypothesis, and the Alpha level
Our Egyptian magistrate gave half of his "subjects" citron, and gave the other half nothing. The hypothesis was that those receiving the citron would survive (at least as long as the experiment and that dose of citron lasted). His hypothesis was supported, but from a statistical viewpoint we are still not sure if this was just due to chance. So now, let's start looking into how we determine if a significant difference exists between groups.
In order to sort out the difference between a chance effect and a statistically significant effect we start by writing a pair of statements called hypotheses: a null hypothesis and the alternative hypothesis. The hypotheses are statements made about what we believe to be true with regards to the population mean (represented by the Greek letter mu ( μ )).
The null hypothesis is a statement of "no effect" meaning whatever effect
- The null hypothesis Hο : μ = μο is a statement of "no effect" meaning whatever effect the researcher suspects may be true is, in fact, not present. If the sample mean turns out to be close, then any small difference can be explained as just due to chance.
- The alternative hypothesis (also called the research hypothesis) Hα : μ ≠ μο is a statement that "there is an effect" due to whatever effect the researcher is investigating. If the sample mean is different enough in value from μο then you can conclude there is a significant effect that is not due solely to chance.
For example, suppose we were told the national cholesterol average for American adults was 195. We then wonder if the average cholesterol level in our city is different from this. We would then make the following hypotheses:
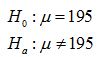
where μ represents the actual true (and unknown to us) average cholesterol level in our city. We would then obtain a random sample of adults from our city, measure their cholesterol, and compute the sample average. Then we would determine whether the sample average differed enough from 195 for us to conclude the cholesterol average in our city was significantly different from the national average.
Through statistical analysis, which we will get to shortly, our job will be to make a decision based on our analysis to either reject the null hypothesis or to fail to reject the null hypothesis. The decision ALWAYS reflects the null hypothesis, and yes, that is the proper wording.
It may seem a little bit backwards to make our decision in terms of the null hypothesis since that hypothesis is based on the notion that what we believe to be true isn't really true! Our legal system provides a good analogy for the logic of this approach. If you are accused of a crime, you are presumed to be innocent (the null hypothesis) until the prosecution can build a strong enough case (the hypothesis test) to reject that presumption in favor of guilt (the alternative hypothesis).
Looking closer, we can now say that the results of the magistrate's experiment led him to the decision to reject the null hypothesis. That is, he found support for a difference between the groups. (At this point we will just pretend it was based on some type of statistical analysis other than alive or dead.)
What if, after receiving the citron, all the subjects in the magistrate's study died anyway? What would our decision be? Now we would have made the decision to fail to reject the null hypothesis. When we fail to reject the null hypothesis we are stating that there was not a significant difference. What? Why can't we just say that we accept the null hypothesis?

The answer goes back to probability. Hypothesis testing is based on inferential probability. This means that our results are never definite. In fact we can only be sure of our decision to a certain degree. In short, with every decision comes a certain degree of risk. The simple fact is that we could select the perfect analysis for a particular situation, conduct it appropriately, and make the correct decision based on those results. It could, however, still be wrong. Chance events occur.
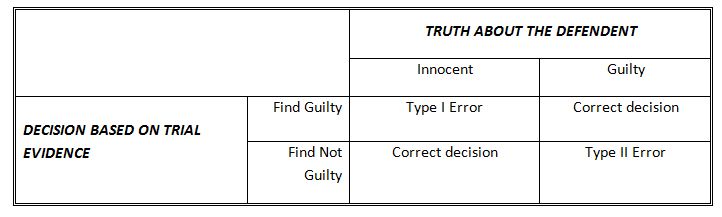
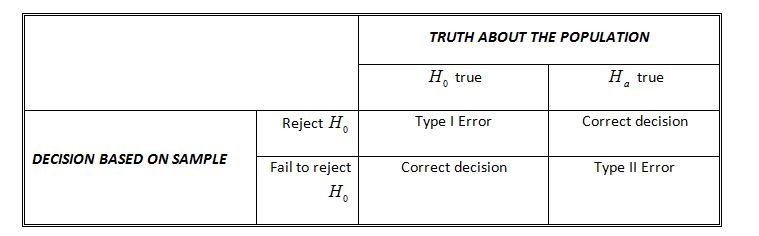
If, based on our results, we make the decision to reject the null hypothesis (indicating that there is a significant difference) but those findings where in fact just due to chance and there really was NOT a significant difference, then we just committed a Type I error.
The reverse of the above situation is also possible. If, again based on our results, we make the decision to fail to reject the null hypothesis (indicating that there is NOT a significant difference) but those findings were again just chance events and there really WAS a significant difference then we just committed a Type II error.
Continuing the analogy of a jury trial, a Type I error would be sending an innocent defendant to prison; and a Type II error would be letting a guilty person go free. The following tables summarize the possible decisions we can make:
With the constant threat of these errors of chance, we as statisticians and researchers must constantly acknowledge the possibility. We do this with the Alpha level. The probability of committing the Type I error is called alpha. As an industry standard, the alpha level is typically set at either 0.05 or 0.01, but generally no higher than 0.05. This means that if the alpha level is set at 0.05 then we are stating that there is a 5% chance of committing a Type 1 error. We could even say that we are 95% sure that this was not the result of chance. However, we did not say that we were 100% sure we were right.
This means that we can never use words like prove, or accept. We only reject, or fail to reject. In the next sections we will go over the concepts of the Z score leading into several types of hypothesis testing.
Before we move on, though, take a moment to make sure you understand all of the concepts and terminology we've covered so far.
Activity not available on mobile devices (description)